
Künstliche Intelligenz verändert derzeit viele kreative Bereiche, auch die Musikproduktion. Was früher professionelle Software, musikalisches Wissen und viel Zeit erforderte, lässt sich heute teilweise automatisieren. Moderne KI-Musikgeneratoren können aus wenigen Textangaben komplette Musikstücke erzeugen.
Dabei reicht oft schon eine kurze Beschreibung oder ein Titel, damit die KI ein passendes Musikstück generiert. Je nach Tool lassen sich Stilrichtungen, Stimmung oder Instrumente vorgeben. Innerhalb weniger Sekunden entsteht so ein fertiger Song oder ein Hintergrundtrack, der sich beispielsweise für Videos, Podcasts oder Social-Media-Inhalte verwenden lässt.
Gerade für Content-Creator, YouTuber oder kleinere Projekte können solche Tools eine interessante Möglichkeit sein, schnell passende Musik zu erzeugen, ganz ohne eigene Musikproduktion.
Die Software im Überblick
Für diesen Artikel verwenden wir eine Software, die verschiedene KI-Funktionen rund um Medienproduktion kombiniert. Neben der automatischen Erstellung von Musik bietet das Programm auch weitere AI-Tools, etwa für Videobearbeitung, Text-zu-Sprache, Untertitel oder andere kreative Anwendungen.
Der Fokus liegt dabei auf einer möglichst einfachen Bedienung. Viele Funktionen lassen sich direkt über kurze Texteingaben steuern. So können Nutzer beispielsweise Musik generieren, indem sie einen Titel eingeben oder eine kurze Beschreibung des gewünschten Songs angeben.
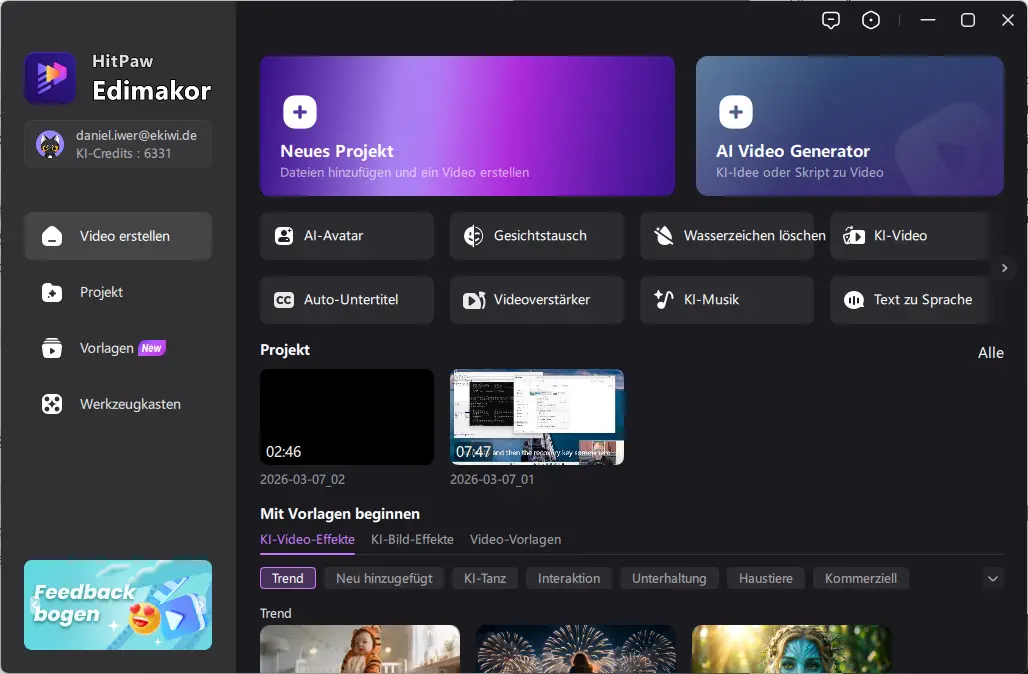
Neben der KI-Musikgenerierung stehen in der Software noch weitere Funktionen zur Verfügung, etwa:
- KI-gestützte Video-Tools
- automatische Untertitel und Übersetzungen
- Text-to-Speech für Voice-over
- verschiedene kreative AI-Werkzeuge für Content-Erstellung
In diesem Artikel konzentrieren wir uns jedoch auf die Musikfunktion und schauen uns an, wie sich mit wenigen Eingaben automatisch ein Musikstück erzeugen lässt.
Musik mit KI generieren
Die eigentliche Erstellung eines Musikstücks erfolgt in der Software über eine sehr einfache Eingabemaske. Statt Noten zu schreiben oder Instrumente einzuspielen, reicht es in vielen Fällen bereits aus, einen Titel oder eine kurze Beschreibung des gewünschten Songs einzugeben.
Die KI nutzt diese Angaben, um daraus ein passendes Musikstück zu generieren. Dabei greifen solche Systeme auf große Datensätze und trainierte Modelle zurück, die verschiedene Musikstile, Rhythmen und Instrumentierungen erkennen und kombinieren können.
Je nach Tool lassen sich dabei unterschiedliche Parameter beeinflussen. Häufig können Nutzer zum Beispiel festlegen:
- den Titel des Songs
- eine Beschreibung oder Stimmung der Musik
- teilweise auch Genre oder Stilrichtung
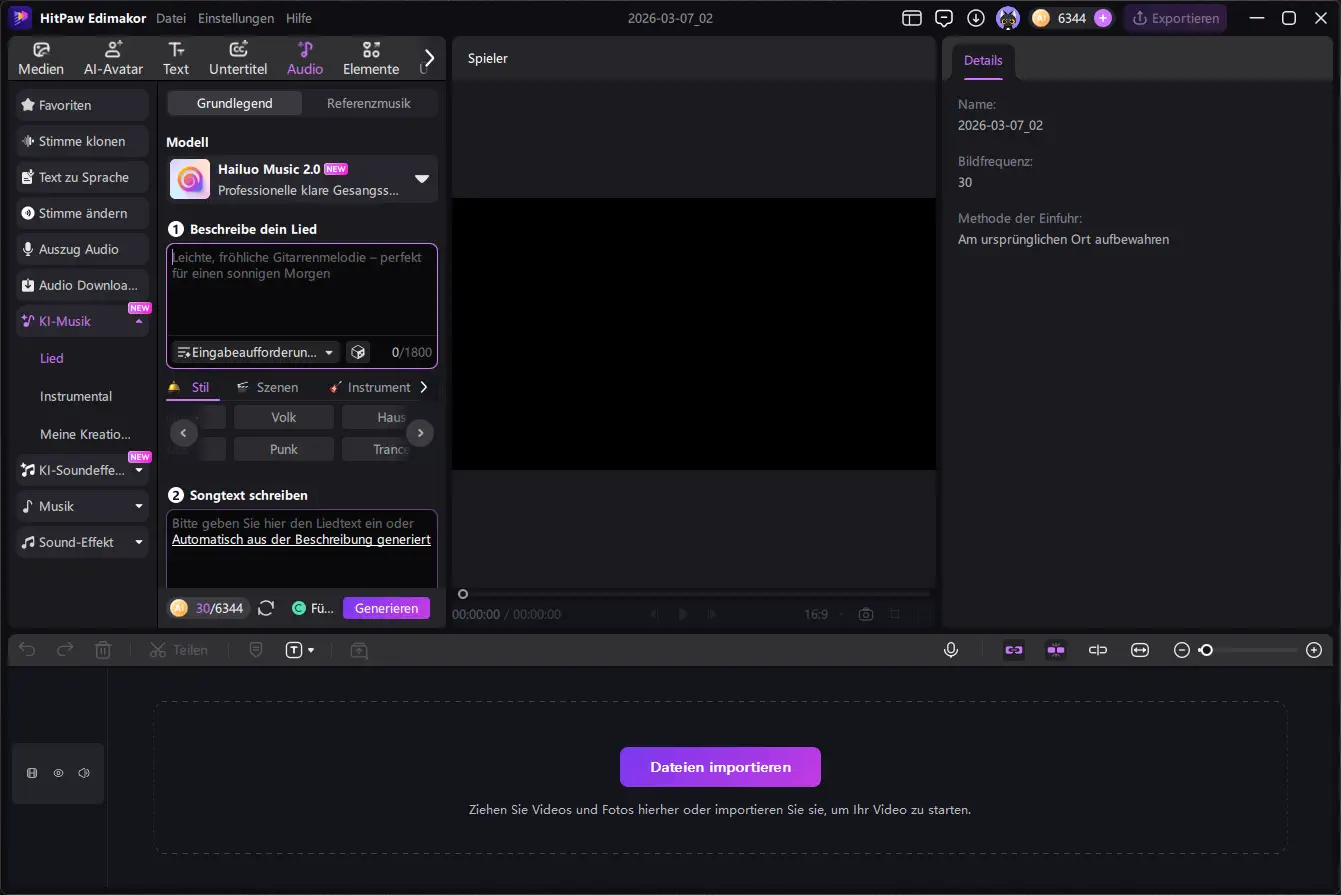
Aus diesen Informationen erstellt die KI anschließend automatisch ein neues Musikstück. Dieser Prozess dauert meist nur wenige Sekunden bis Minuten.
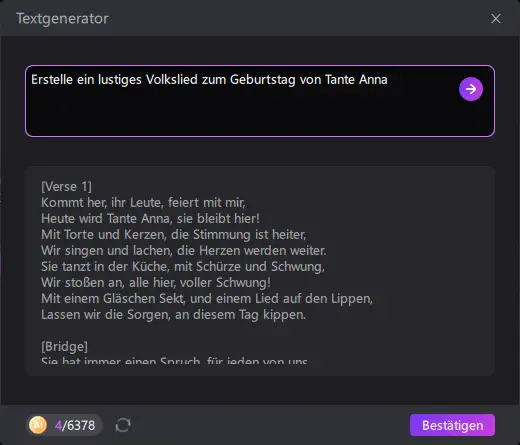
Der Vorteil solcher KI-Musikgeneratoren liegt vor allem in der Geschwindigkeit und Einfachheit. Auch ohne musikalische Vorkenntnisse lassen sich schnell Hintergrundtracks oder einfache Songs erzeugen. Gerade für Content-Creator, Präsentationen, Videos oder Podcasts kann das eine praktische Lösung sein, um passende Musik zu erstellen, ohne auf klassische Musikproduktion angewiesen zu sein.
Natürlich ersetzt eine KI-generierte Komposition nicht unbedingt professionelle Musikproduktion. Dennoch sind die Ergebnisse inzwischen erstaunlich brauchbar und können für viele Anwendungsfälle eine schnelle und unkomplizierte Alternative darstellen.
Text zu Sprache: KI erstellt automatisch Voice-over
Neben der Musikgenerierung bietet die Software auch eine Text-zu-Sprache-Funktion (Text-to-Speech). Damit lassen sich aus geschriebenem Text automatisch gesprochene Audiospuren erzeugen, die beispielsweise als Voice-over für Videos, Präsentationen oder Tutorials verwendet werden können.
Der Ablauf ist dabei relativ einfach: Zunächst wird der gewünschte Text in ein Eingabefeld eingefügt. Anschließend kann aus einer Bibliothek verschiedener KI-Stimmen gewählt werden. Diese unterscheiden sich unter anderem nach Sprache, Geschlecht, Alter oder Einsatzbereich, etwa für Erklärvideos, Werbung oder Erzählerstimmen.
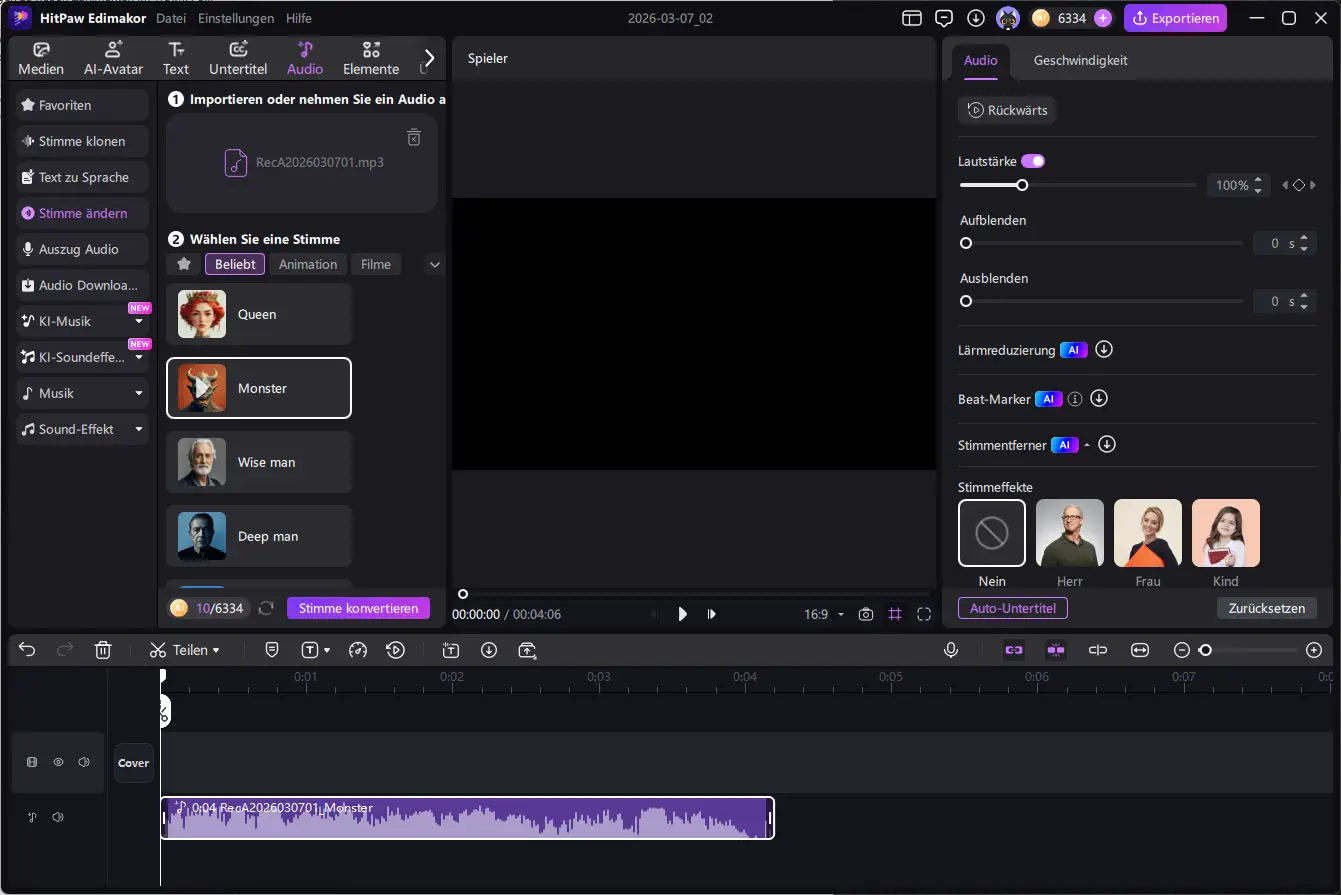
Nachdem eine passende Stimme ausgewählt wurde, erzeugt die Software automatisch eine Audiodatei aus dem eingegebenen Text. Diese wird direkt in das Projekt eingefügt und kann anschließend wie jede andere Tonspur bearbeitet werden.
Zusätzlich stehen verschiedene Optionen zur Verfügung, um den Klang anzupassen. Dazu gehören beispielsweise:
- Lautstärkeanpassungen
- Ein- und Ausblenden der Audiospur
- verschiedene Stimmeffekte
- KI-gestützte Audiofunktionen zur Optimierung der Tonspur
- Eigene Stimme automatisch abändern
Gerade für Content-Creator oder kleinere Videoprojekte kann diese Funktion sehr praktisch sein. Statt selbst ein Voice-over aufzunehmen, lässt sich schnell eine automatisch generierte Sprecherstimme erstellen, die direkt im Video verwendet werden kann.
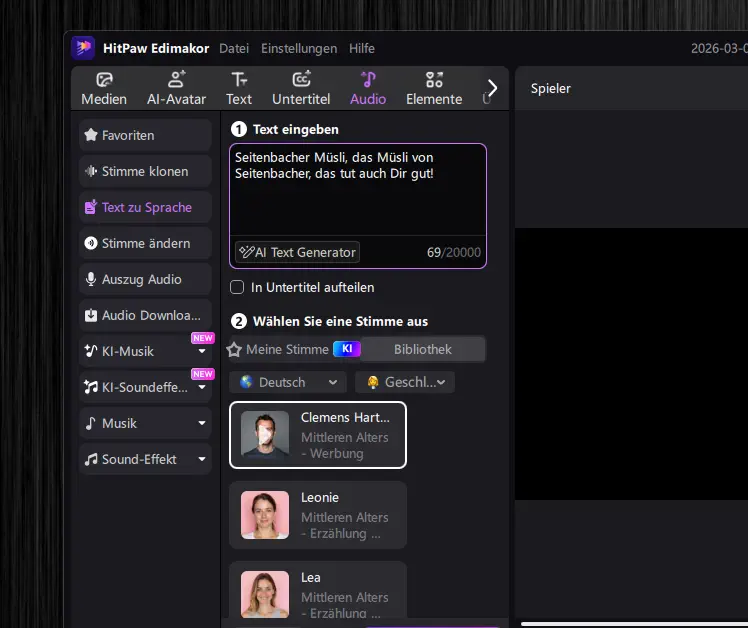
KI-Audiofunktionen im Editor kombinieren
Die verschiedenen KI-Audiofunktionen lassen sich direkt im integrierten Editor miteinander kombinieren. Generierte Sprachaufnahmen, Musik oder andere Audiodateien können in einer Timeline angeordnet und gemeinsam bearbeitet werden.
Dabei lassen sich Spuren schneiden, verschieben oder in der Lautstärke anpassen. So kann beispielsweise eine Text-zu-Sprache-Spur mit Musik oder Soundeffekten kombiniert werden. Auf diese Weise entsteht aus den einzelnen KI-Elementen schnell eine fertige Audiospur.
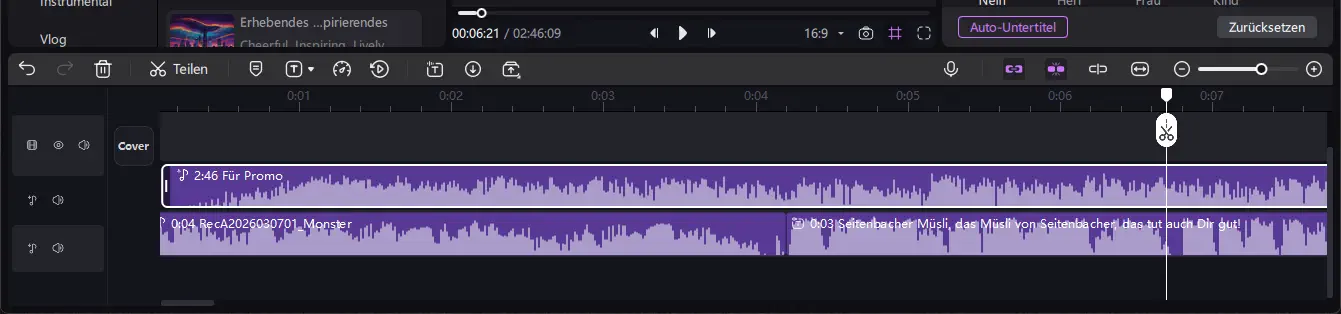
Eigene Stimme imitieren
Eine weitere Funktion der Software ist das Klonen der eigenen Stimme. Dabei wird eine kurze Sprachaufnahme erstellt, die von der KI analysiert wird. Auf Basis dieser Aufnahme kann die Software anschließend eine synthetische Version der Stimme erzeugen.
Der Ablauf ist einfach: Der Nutzer spricht einen vorgegebenen Beispieltext ein, damit die KI Klang, Tonlage und Sprechweise analysieren kann. Anschließend lässt sich diese Stimme für weitere Inhalte verwenden, etwa für automatisch generierte Sprachaufnahmen oder Voice-over.
So können Texte später von einer KI-Version der eigenen Stimme gesprochen werden, ohne dass jede Aufnahme erneut eingesprochen werden muss.
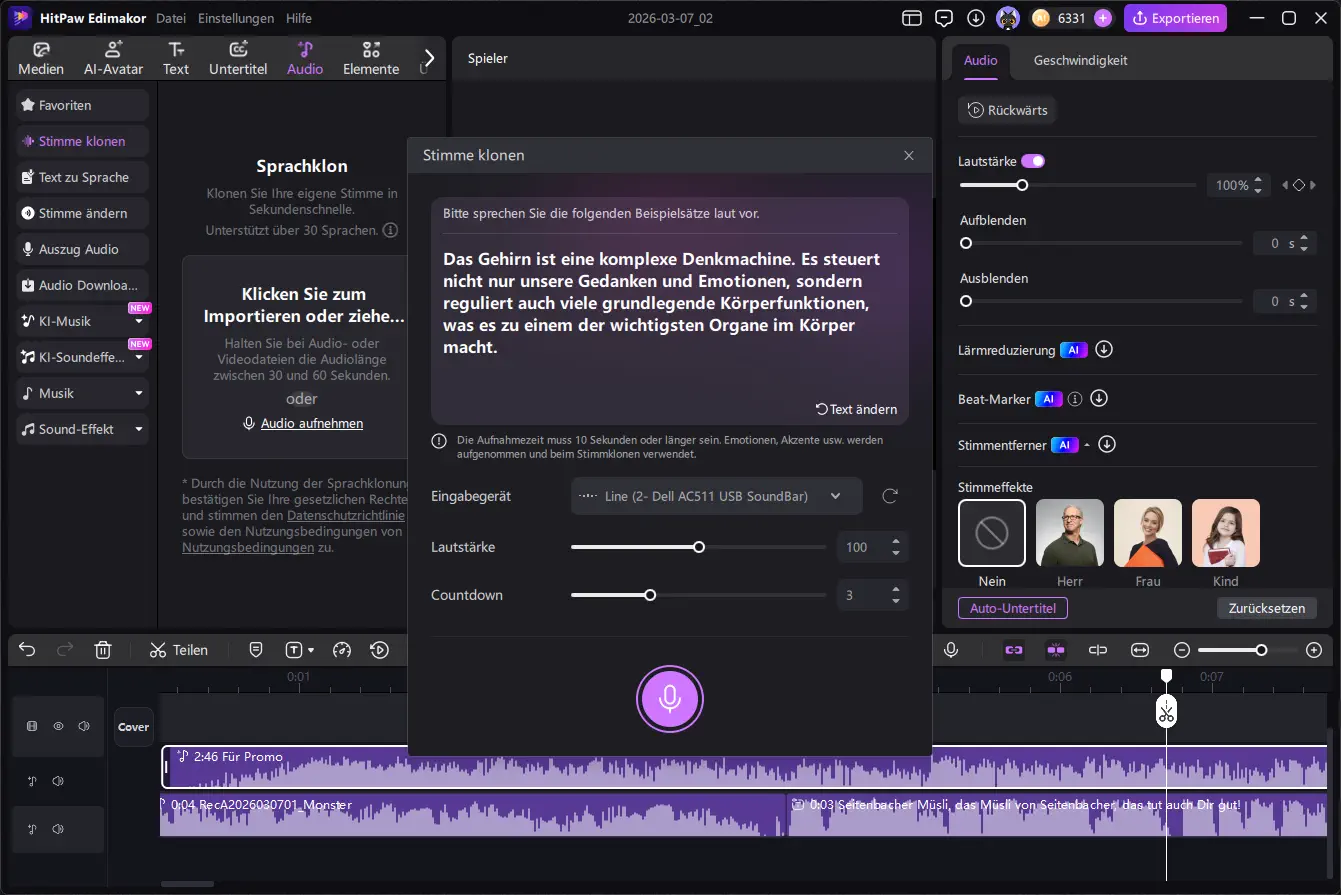
Audio exportieren
Ist die Audiospur erstellt, lässt sie sich anschließend direkt exportieren. Die Software bietet dafür verschiedene Audioformate, darunter etwa MP3, WAV, M4A oder AIFF. Dadurch kann die erzeugte Sprachaufnahme flexibel weiterverwendet werden, beispielsweise für Videos, Podcasts oder Präsentationen.
Der Export erfolgt über einen einfachen Dialog, in dem Dateiname, Speicherort und gewünschtes Format ausgewählt werden. Anschließend wird die generierte Audiodatei erstellt und kann in anderen Projekten oder Schnittprogrammen weiterverarbeitet werden.
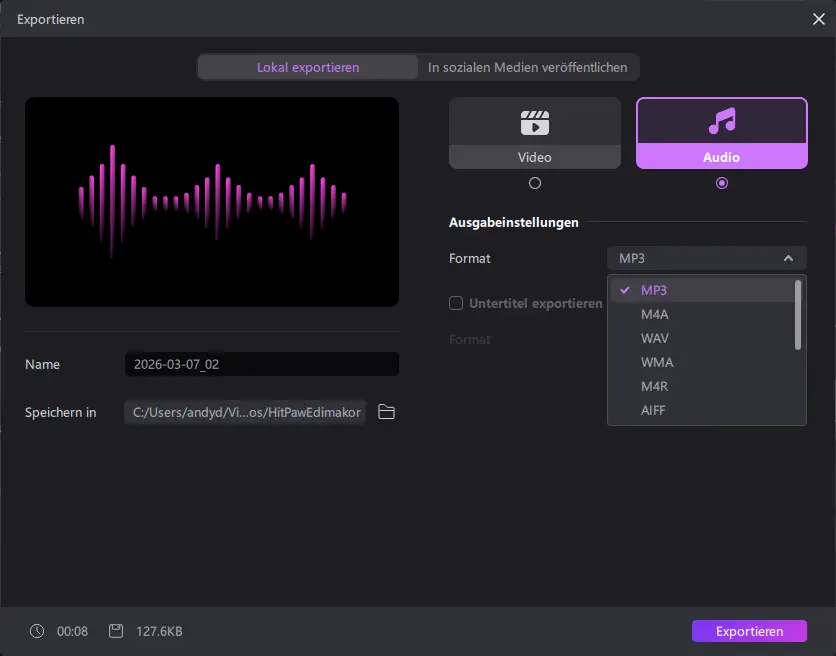
Fazit
Moderne KI-Tools ermöglichen heute viele Schritte der Audio- und Medienproduktion automatisch. Programme wie HitPaw Edimakor kombinieren dabei verschiedene Funktionen in einer einzigen Anwendung, von KI-Musikgeneratoren über Text-zu-Sprache bis hin zum Stimmenklonen. Dadurch lassen sich Musik, Sprachaufnahmen und andere Audioelemente relativ schnell erstellen und anschließend direkt im Editor weiter bearbeiten. (HitPaw Edimakor)
Gerade für Content-Creator, Videos oder Podcasts kann das eine praktische Lösung sein, um ohne großen Produktionsaufwand passende Musik oder Voice-over zu erstellen. Die erzeugten Inhalte lassen sich anschließend exportieren und flexibel in anderen Projekten weiterverwenden.
Auch wenn KI-generierte Inhalte nicht immer perfekt sind, zeigen solche Tools bereits deutlich, wie stark sich Audio- und Medienproduktion durch künstliche Intelligenz verändert.